Paramétrer la génération des noms
Règles de construction des noms
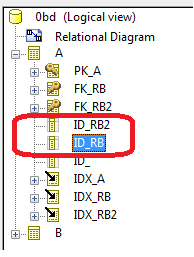
Les noms des objets physiques créés lors de la synchronisation "logique vers physique" sont déduits du Nom Local des objets logiques dont ils sont issus.
Les noms des objets logiques (classe, association, partie, attribut, rôle) n'étant soumis à aucune restriction particulière, des règles de transformation s'appliquent par défaut lors de leur synchronisation. Ces règles sont accessibles localement dans la page Options > Standard des propriétés de la base de données synchronisée, ou globalement dans les propriétés des SGBD cibles :
• Taille identifiant : taille maximale d'un identificateur SQL pour ce SGBD cible.
• 1er caractère : jeu de caractères autorisé pour le 1er caractère d'un identificateur SQL.
• Caractères autorisés : jeu de caractères autorisé pour les caractères d'un identificateur SQL.
• Caractère de remplacement : caractère de remplacement des caractères non autorisés.
• Caractères convertis : jeu de caractères à convertir d'un identificateur SQL.
• Caractères de conversion : jeu de caractères correspondant aux caractères à convertir.
• Conversion majuscule : conversion en majuscules des identificateurs SQL.
Il est possible d'indiquer un autre nom pour chaque objet synchronisé à l'aide de son Nom SQL. Le Nom SQL se substitue au Nom Local lors de la synchronisation, tout en tenant compte des règles de transformation par défaut.
Le Nom SQL des objets logiques est accessible dans la page Génération > SQL (ou page SQL) de leur fenêtre de propriétés.
Vous pouvez donner un nom différent selon la base de données ou le SGBD.
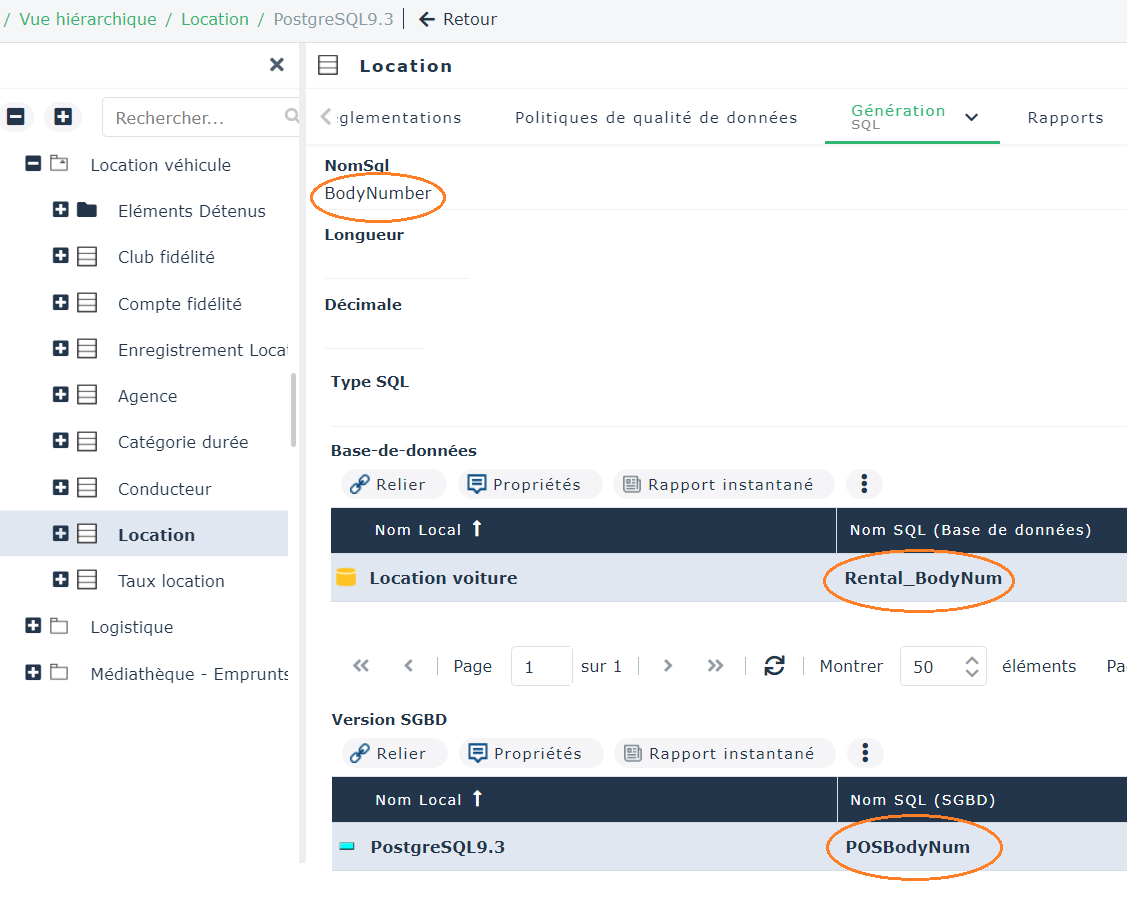
Lorsque les champs Nom SQL (Base de données) et Nom SQL (SGBD) indiquent des noms différents, c'est le nom défini au niveau de la base de données qui prévaut lors de la synchronisation.
Par défaut, les noms des objets relationnels sont générés selon les masques suivants :
Table | Préfixe de la base de données + nom* de l'entité ou de l'association |
Colonne | Nom* de l'attribut |
Clé primaire | "PK_" + nom* de l'entité ou de l'association |
Clé étrangère | "FK_" + nom* de l'entité cible ou du rôle si renseigné |
Index de clé primaire | "IDX_" + nom* de l'entité ou de l'association |
Index de clé étrangère | "IDX_" + nom* de l'entité cible ou du rôle si renseigné |
*Nom calculé selon les règles de construction expliquées précédemment.
Ces masques peuvent être modifiés localement dans chaque base de données, ou globalement pour un SGBD cible donné.
Modifier une règle de construction
Pour modifier le masque d'une règle de construction de nom :
1. Faites un clic droit sur la base de données et sélectionnez Propriétés.
2. Cliquez sur la liste déroulante puis sur Options > Synchronisation.
3. Dans le champ de la règle en question, cliquez sur la flèche.
4. 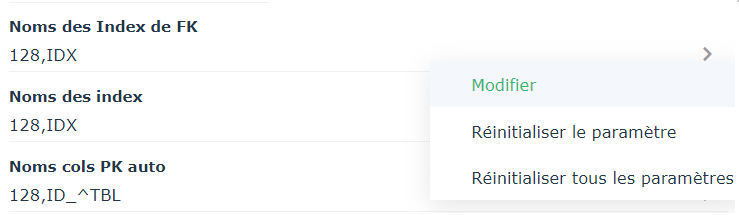 Cliquez sur Modifier.
Cliquez sur Modifier.
Cliquez sur Modifier. La fenêtre de Saisie du masque SQL est présentée.
Saisie du masque SQL
Les masques SQL définissent la règle de construction des noms des objets relationnels lors de la synchronisation.
Exemple : dans la base BASE_EMPLOYES qui a pour préfixe EMP, le masque ^DB_^ROOT génère pour la table issue de l'entité Client : EMP_CLIENT.
Dans la fenêtre de saisie du masque SQL, vous pouvez saisir directement le Masque, en utilisant la syntaxe indiquée ci-après, mais vous pouvez également utiliser l'aide à la saisie proposée par le cadre Composant.
^ROOT | • Pour une table : nom* de la classe, de l'association ou de la partie dont elle provient. • Pour une colonne : nom* de l'attribut ou nom de l'identifiant. • Pour une clé primaire : nom* de la classe, de l'association ou partie dont elle provient. • Pour une clé étrangère : nom* de la classe cible ou du rôle si renseigné. • Pour une colonne de FK : nom* de l'attribut. • Pour une colonne de PK auto : nom* de l'identifiant de la classe. • Pour un index sur clé primaire : nom* de la classe, de l'association ou de la partie. • Pour un index sur clé étrangère : nom* de la classe cible ou du rôle si renseigné. • Pour un index : nom* de l'attribut, du rôle ou de la classe. |
^DB | Préfixe de la base de données |
^EXT | • Pour une clé étrangère : nom* de l'association, de la partie ou de la généralisation • Pour un index sur clé étrangère : nom* de l'association, de la partie ou de la généralisation |
^TBL | Nom local de la table ou nom local de la table de référence |
^TBO | • Pour une clé étrangère : nom* de la classe, de l'association ou de la partie dont elle provient • Pour un index sur clé étrangère : nom* de la classe, de l'association ou de la partie d'origine |
^TBR | Nom de la table de référence |
^KEY | Nom de la clé étrangère |
^CPT | Composteur |
*Nom calculé selon les règles de construction expliquées précédemment.
La Taille indique la longueur limite totale du nom généré. Elle est également disponible pour chacun des éléments utilisés, qui seront tronqués au nombre de caractères indiqué entre parenthèses après l'élément concerné.
La définition d'un Composteur ("^CPT") permet de générer automatiquement un numéro d'ordre, et d'en indiquer la longueur (par exemple, ^CPT[^1^] générera "1", "2", "3"; ^CPT[^3^] générera "001", "002", "003").
L'option Toujours indique que le compostage commence dès la première occurrence (CLI00, CLI01, .., au lieu de CLI, CLI01,…,).
Vous pouvez également préciser les caractères utilisés comme préfixe et suffixe de ce composteur.
L'option Unicité du nom permet de garantir l'unicité du nom d'un objet au niveau de la base de données, du référentiel ou de la table dans lesquels se trouve cet objet. Ainsi, lorsque vous définissez l'unicité de nom au niveau de la table, il n'est pas possible d'attribuer un même nom à des objets différents au sein d'une même table.
Paramétrer le nom des colonnes de PK (identifiant implicite)
Lors de la synchronisation en mode Logique > Physique, l'identifiant de l'entité devient la clé primaire de la table. Si l'identifiant est implicite, une colonne est automatiquement créée. Pour plus de détails, voir Règles de synchronisation "logique vers physique".
Par défaut le nom d'une colonne issue d'un identifiant implicite est construit à l'aide du mot clé ^TBL qui correspond :
• au nom de la table migrante (autrement dit issue d'une clé étrangère) si l'identifiant est migrant
• au nom de la table si l'identifiant n'est pas migrant
Vous pouvez modifier les règles de construction et construire le nom de ces colonnes avec le mot clé ^KEY qui correspond au nom de la clé étrangère (sans " FK_ ") si l'identifiant est migrant, ainsi qu'avec le mot clé ^ROOT qui correspond au nom de l'identifiant (ID). Voir Modifier une règle de construction.
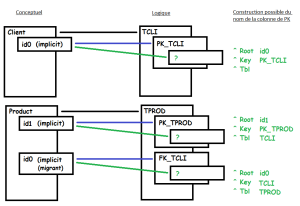
Exemple
Lorsqu'il existe deux associations contraintes entre deux entités comme ci-dessous :
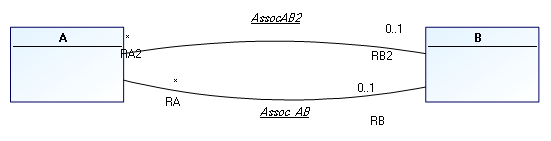
Par défaut, après synchronisation, vous obtenez deux colonnes avec des noms identiques seulement différenciés par le préfixe "1".
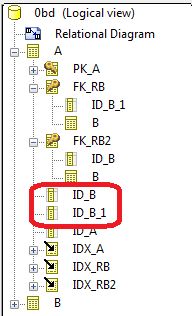
Vous pouvez modifier la règle de nommage et construire le nom de ces colonnes avec le mot clé ^KEY qui correspond au nom de la clé étrangère (sans " FK_ ").
Le nom de la clé étrangère étant calculé sur le nom du Rôle lorsqu'il est renseigné, alors le nom obtenu pour les deux colonnes sera différent.
Dans notre exemple, si vous remplacez "ID^TBL" par "ID^KEY" vous obtenez après synchronisation :