Extraire la description de schémas de bases de données à partir de sources de données
HOPEX Data Source Extractor est une application qui utilise les API ODBC pour extraire la définition du schéma d'une base de données. Cette description, obtenue en format structuré, peut être ensuite utilisée pour la rétro-génération dans HOPEX ou pour la génération en mode modification.
L'outil d'extraction est disponible en version 64 bits.
Il peut être déployé séparément de HOPEX.
Configuration des sources de données requise
Pour utiliser HOPEX Data Source Extractor, vous devez disposer de l'outil ODBC Data Sources Administrator (64 bits). Cet outil Microsoft est installé avec Windows et est accessible dans le menu Démarrer.
Télécharger HOPEX Data Source Extractor
Pour installer l'outil, assurez-vous de disposer des droits d'installation sur le poste.
HOPEX Data Source Extractor est disponible sur l'HOPEX Store de MEGA. Pour le télécharger :
1. Rendez-vous sur l'HOPEX Store, à l'adresse suivante : https://store.mega.com/modules.
2. Sélectionnez le module HOPEX Data Source Extractor.
3. Décompressez le fichier sur un poste qui a accès à la base de données concernée.
Lancer l'extraction de données
Pour l'extraction de données, il est nécessaire de définir une source de données ODBC avec l'outil ODBC Data Source Administrator :
1. Lancez l'outil ODBC Data Source Administrator.
2. Cliquez sur l'onglet Drivers.
3. Sélectionnez le pilote et cliquez sur OK.
Le pilote de la base de données doit avoir un niveau de conformité ("conformance level") supérieur ou égal à 1. Le champ d'extraction des objets dépend du pilote utilisé dans la définition de la source de données ODBC.
Pour extraire la description d'une base de données :
1. Lancez l'utilitaire HOPEX Data Source Extractor (dans le répertoire indiqué lors du téléchargement du module).
Un assistant apparaît.
2. Sélectionnez le type de source de données dont vous souhaitez extraire la description du schéma.
Les principaux SGBD supportés sont présentés, vous pouvez afficher les autres types de source de données en cliquant sur Other Data Source Types.

3. Cliquez sur Next.
La liste des sources de données correspondantes apparaît.
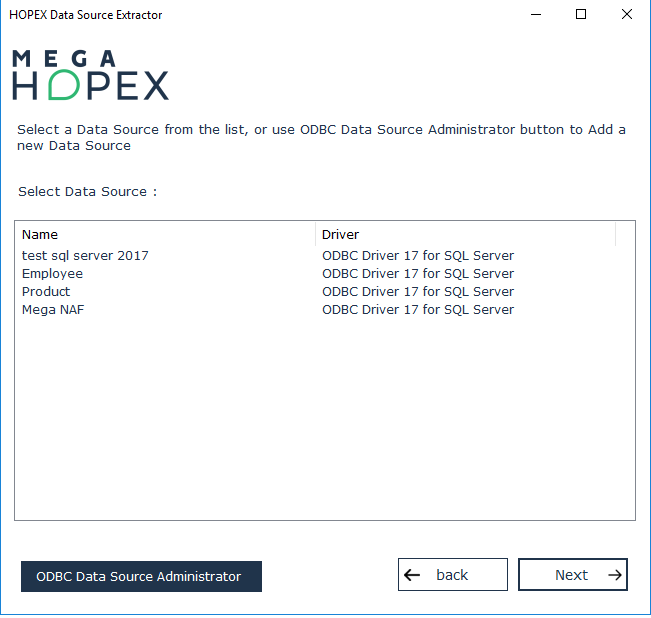
4. Sélectionnez une source de données et cliquez sur Next.
La fenêtre de connexion s'affiche.
5. S'il ne sont pas déjà définis au niveau de la source de données, précisez un code utilisateur (User ID), un mot de passe (Password) et un nom de serveur (Server name). Si d'autres paramètres sont requis par le pilote ODBC, ils sont demandés lors de la connexion.
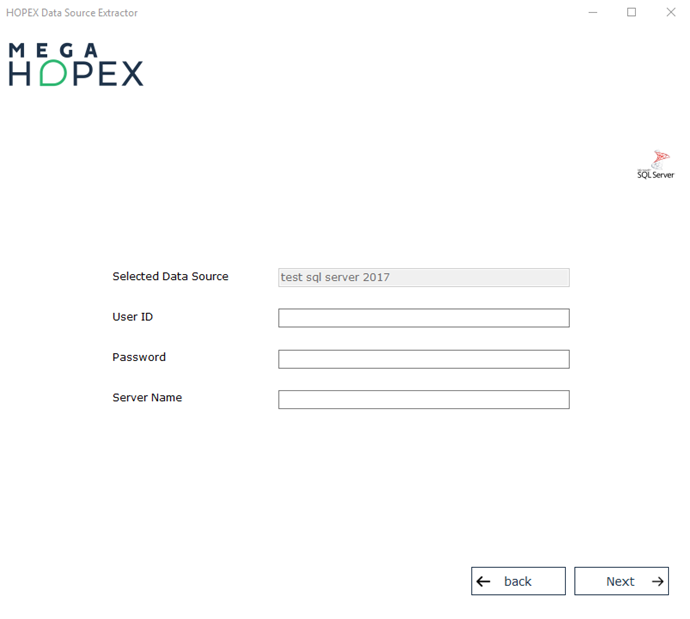
6. Cliquez sur Next pour valider la connexion.
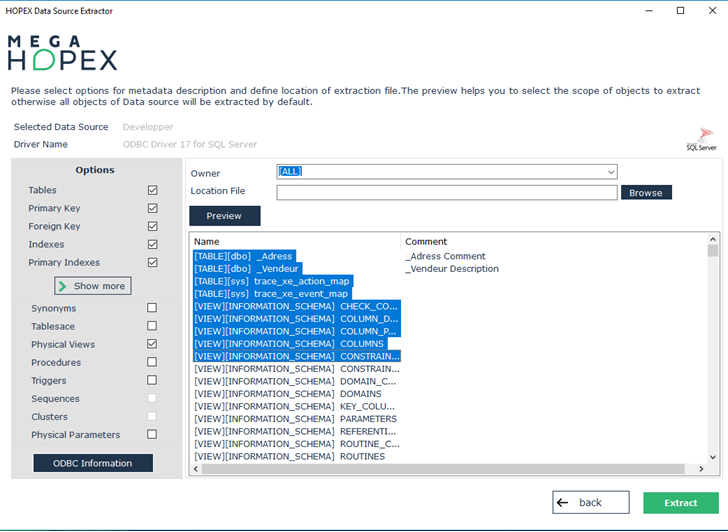
Une fois la connexion établie, vous pouvez choisir les options d'extraction.
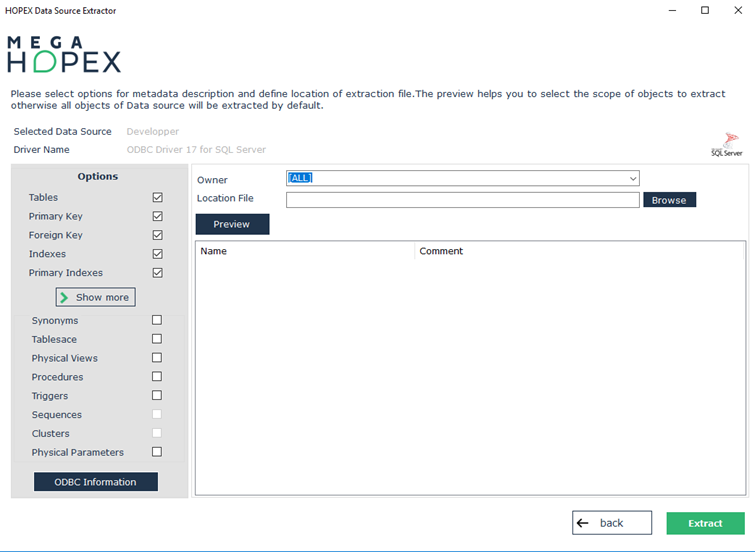
7. Sélectionnez les éléments à extraire, en plus des tables et des colonnes. Par défaut, ces éléments sont tous sélectionnés.
Toutes les tables auxquelles l'utilisateur a accès, qu'elles lui appartiennent ou non, sont présentées. Les tables synonymes peuvent également apparaître si la case correspondante a été cochée.
Il est possible de filtrer les tables par propriétaire (Owner), en le sélectionnant dans la zone correspondante. L'affichage de la liste des propriétaires, ainsi que celle de leurs tables peut prendre plusieurs secondes.
Les éléments suivants sont inclus dans l'extraction :
• Clés primaires (Primary keys).
• Clés étrangères (Foreign keys).
• Index (Index) : il s'agit des index qui ne portent pas sur des clés primaires.
• Index primaires (Primary index) : il s'agit des index qui portent sur des clés primaires.
Le champ Destination file permet de préciser le chemin et le nom du fichier d'extraction ; le bouton Browse permet de parcourir les dossiers.
8. Après sélection des options d'extraction, appuyez sur Extract pour démarrer le traitement.
Un message rend compte du nombre de tables extraites. L'activation du bouton Warnings permet de consulter simultanément le compte-rendu.
Il est possible de visualiser la liste des tables accessibles en activant le bouton List Tables, et d'extraire uniquement les tables sélectionnées par l'utilisateur dans la liste alors obtenue (toutes les tables sont sélectionnées par défaut).
A la fin de l'extraction, le bouton Open file permet de consulter le résultat. Le fichier de compte-rendu est disponible à l'emplacement {AppData d'utilisateur courant}/Local/Mega.
Le fichier résultat peut être exploité par la rétro-génération (voir Rétro-générer des tables). Il contient la description de la base sous forme d'objets HOPEX.
Une fois l'opération d'extraction terminée :
Fichier de compte-rendu de l'extraction
Le fichier de compte-rendu de l'extraction des tables par l'utilitaire d'extraction ODBC s'appelle <FIC>_CRD.TXT où <FIC> représente les trois premiers caractères du nom du fichier résultat.
Il contient la liste des tables relues.
Exemple :
==================================================
Data Source Extracting : DATASOURCE
==================================================
Table : OWNER.NOMTABLE1
Table : OWNER.NOMTABLE2
(suite)
==================================================
End of extraction
==================================================
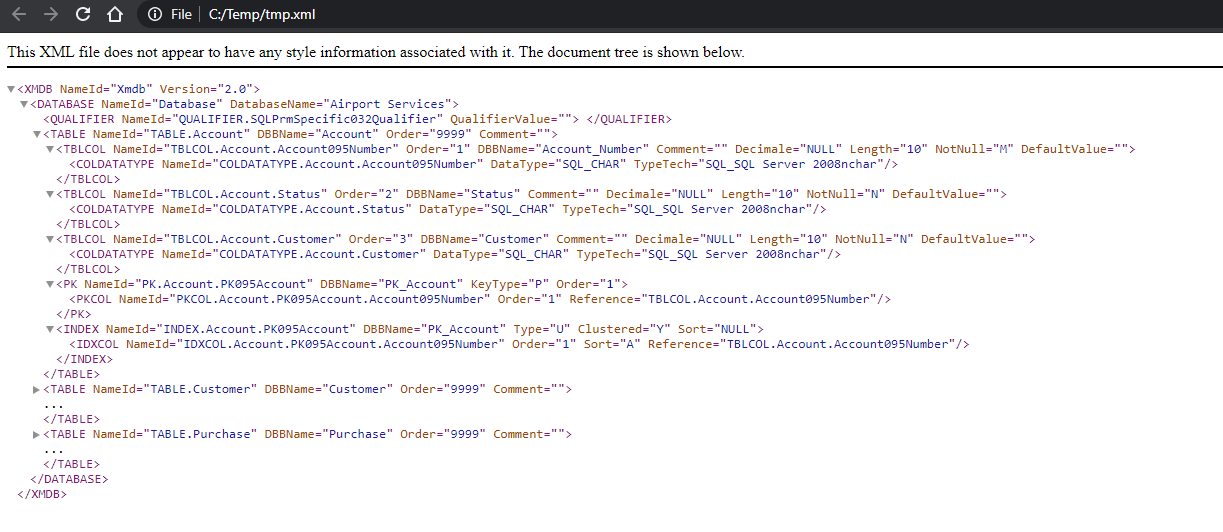
Fichier résultat de l'extraction
Le fichier résultat de l'extraction contient la description des tables et des colonnes, résultat de la relecture. Ce fichier porte l'extension ".xml".
Exemple de fichier d'extraction :