Tests de performance et santé
HOPEX vous permet de générer quotidiennement le rapport de santé d'un référentiel. Ce rapport permet de détecter :
• les anomalies de performance ou d'usage que peuvent rencontrer les utilisateurs au quotidien.
• tout changement significatif.
Pour cela des tests de performance et de santé sont réalisés quotidiennement. Des événements sont générés en cas d'anomalies détectées.
Description des tests
Description des tests de performance de l'infrastructure
Des scénarios standards d'utilisation d'HOPEX sont réalisés tous les après-midi (job "RepositoryHeath Daily Afternoon Trigger", 16:00 GMT) :
• Lecture de 1000 objets volumineux (BLOB) existants.
• Exploration d'un graphe existant (1000 objets et 500 MetaAssociations).
• Requête ERQL sur un graphe existant (1000 objets et 500 MetaAssociations).
• Ecriture de 1000 textes volumineux (BLOB).
• Création d'un graphe de 1000 objets et 500 MetaAssociations.
• Suppression d'un graphe de 1000 objets et 500 MetaAssociations.
• Requête ERQL sur un graphe créé récemment (1000 objets et 500 MetaAssociations).
Chaque scénario génère un résultat qui est stocké dans le référentiel. Ces résultats sont analysés ultérieurement tous les jours (job "RepositoryHeath Daily Evening Post Trigger", 23:05 GMT) afin de détecter toute anomalie.
Un historique de 30 résultats est nécessaire avant de pouvoir générer une alerte.
Description des tests de santé des référentiels
L'analyse de certains usages est capitale pour identifier tout ce qui pourrait compromettre l'intégrité des données, que ce soit au quotidien ou suite une mise à jour d'HOPEX.
Pour tous les référentiels de tous les environnements, les vérifications suivantes sont effectuées tous les soirs (job "RepositoryHeath Daily Evening Trigger", 23:00) :
• Administration
• vérification de compatibilité entre la structure SQL des données et la version du serveur
• fragmentation des tables
• fragmentation des index
• exécution du plan de maintenance SQL
• Personnalisation
• modification des données HOPEX
• volumétrie des données HOPEX
• Utilisation
• volumétrie des espaces de travail
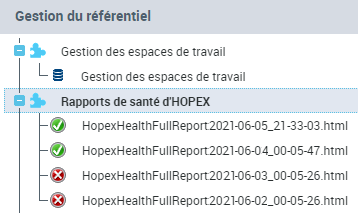
Visualiser les rapports de santé d'HOPEX
Accéder aux rapports de santé quotidiens d'HOPEX
Le bureau d'Administration donne accès aux rapports de santé quotidiens d'HOPEX. Chaque rapport contient les anomalies détectées sur toutes les machines, sur tous les référentiels.
Les rapports sont listés chronologiquement (le plus ancien en premier) au format suivant :
HopexHealthFullReportAAAA-MM-JJ_hh-mm-ss.html
avec : AAAA : année, MM : mois, JJ :jour, hh : heures, mm : minutes, et ss : secondes.
L'icône du rapport est représenté par :
•  si le rapport de santé ne contient pas d'anomalies
si le rapport de santé ne contient pas d'anomalies
si le rapport de santé ne contient pas d'anomalies•  si le rapport de santé contient des anomalies
si le rapport de santé contient des anomalies
si le rapport de santé contient des anomaliesPour visualiser les rapports de santé quotidiens d'HOPEX:
1. Connectez-vous au bureau d'Administration.
2. Dans le volet Gestion du référentiel > Rapports de santé d'HOPEX, cliquez sur le rapport qui vous intéresse (le dernier rapport se trouve en haut de la liste).
Le rapport s'affiche dans un nouvel onglet de votre navigateur.
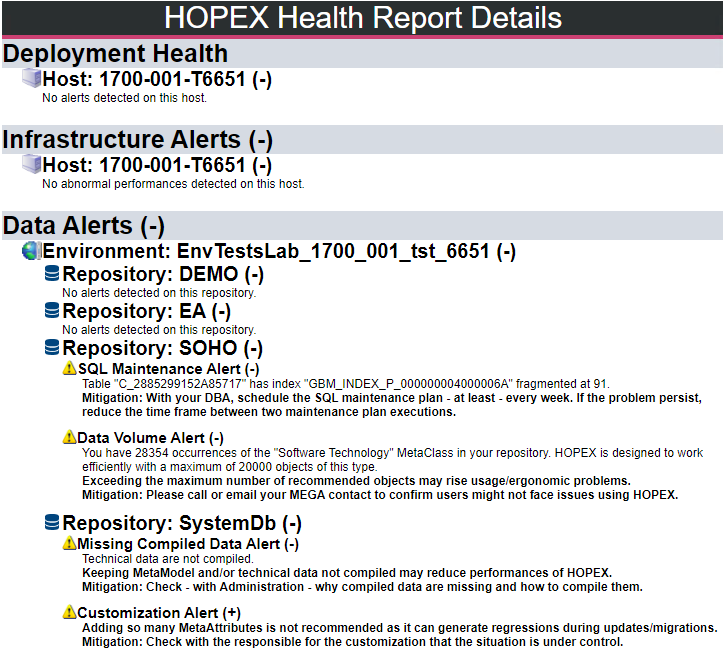
3. Cliquez sur (+)/(-) en regard du nom de la machine, de l'environnement, du référentiel, ou de l'alerte pour afficher/masquer ses détails.
Description du rapport de santé d'HOPEX
Le rapport de santé d'HOPEX contient la description succincte des problèmes détectés au niveau des performances ou des usages. Il présente les alertes détectées au niveau :
• des infrastructures (Infrastructure Alerts)
• des données (Data Alerts) pour chaque référentiel de chaque environnement
Exemple : détection de trois alertes ("Query Execution Alert", "Macro Execution Alert" et "Data Volume Alert") au niveau des données, sur le référentiel "Soho".
